
(아직) 컴퓨터가 당신을 대체하지 못하는 이유
-옮긴이: 이 글은 하버드 대학 경제학과 센딜 뮬레이네이선(Sendhill Mullainathan) 교수가 뉴욕타임스에 기고한 글입니다.
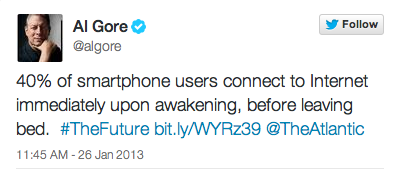
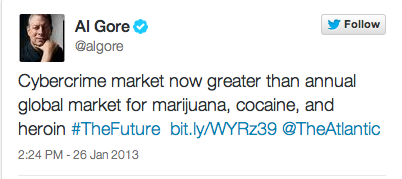
당신은 위의 두 가지 트윗 중에서 어떤 글이 더 많이 리트윗되었을 것으로 생각하나요? 세 명의 컴퓨터 과학자는 최근 발표한 논문에서 트위터에서 어떤 글이 더 많이 리트윗되는지를 예상하는 알고리즘을 만들었습니다. (이 알고리즘에 근거해서 뉴욕타임스는 25개 질문이 있는 퀴즈를 만들었는데, 관심 있는 분들은 직접 풀어보기 바랍니다. 앨 고어가 남긴 위의 트윗 중에는 첫 번째 트윗이 더 많이 리트윗되었습니다.) 어떤 글이 더 많이 리트윗될지를 예상하는 알고리즘은 빅 데이터의 힘을 보여주는 동시에 빅 데이터가 가진 근본적인 한계를 보여주기도 합니다. 구체적으로 어떤 트윗이 많이 리트윗될지를 예측하는 것은 리트윗될 만한 트윗을 만들어내기보다 훨씬 쉽다는 것입니다. 앞서 언급한 세 명의 과학자는 같은 사람이 같은 링크에 대해 다르게 표현한 11,000쌍의 트윗을 생성해서 어떤 단어 사용 패턴이 더 많은 리트윗을 유발하는지를 데이터를 통해서 확인한 뒤 알고리즘을 만들고 새로운 데이터에서 이 알고리즘이 잘 작동하는지를 평가했습니다. 어떤 트윗이 리트윗이 많이 될지를 이 알고리즘을 사용한 경우 67%를 맞췄고, 사람들은 61%를 맞췄습니다. 아무런 다른 지식이 없는 기계 알고리즘이 오랜 시간 다양한 지식과 정보를 습득해온 사람보다 더 높은 확률로 예측했다는 것은 놀라운 일입니다. 기계 알고리즘은 트윗의 길이나 “retweet” 혹은 “please”와 같은 단어가 사용되었는지 등 몇 가지 특징만을 토대로 놀라운 예측력을 보였습니다. 이는 빅 데이터가 가져다준 기적 중 하나입니다.
하지만 우리는 기계가 우리를 대신할 것이라고 단언할 필요는 없습니다. 앞서 소개한 리트윗 예측 알고리즘은 무척 놀랍지만 모든 예측 알고리즘이 공유하는 아킬레스건이 여기에도 존재합니다. 우리가 어떤 트윗이 더 많이 리트윗될지를 예측하는 데 관심을 두는 이유는 더 나은 트윗을 작성하고 싶어서입니다. 그리고 우리는 이 두 가지가 연관되어 있다고 생각합니다. 만약 넷플릭스가 내가 어떤 영화를 좋아하는지를 예측할 수 있다면 넷플릭스는 더 나은 TV 프로그램을 만드는 데 비슷한 알고리즘을 이용할 수도 있습니다. 하지만 실제는 이론처럼 간단하지 않습니다. 예측을 잘하는 것은 종종 사람들이 좋아하는 제품이나 서비스를 만들어내는 것으로 이어지지 않기 때문입니다. 그 이유 중 하나는 바로 가장 오래된 통계학의 문제와 연관되어 있습니다. 상관관계(correlation)는 인과관계(causation)가 아닙니다. 예를 들어 리트윗 예상 알고리즘이 길게 쓴 트윗이 더 많이 리트윗된다는 것을 발견했다고 합시다. 그렇다고 해서 당신이 무조건 트윗 길이를 늘리면 되는 것은 아닙니다. 이 맥락에서 트윗의 길이가 리트윗 수를 예상하는 데 좋은 변수가 되는 이유는 바로 긴 트윗일수록 더 많은 내용을 담고 있는 경우가 많기 때문입니다. 따라서 우리가 이 사례에서 배워야 하는 것은 “긴 트윗을 써라”가 아니라 “더 많은 내용을 담아라”일 것입니다.
또 다른 문제는 무엇이 사람들의 흥미를 끌 것인지 예측하는 것에 내재한 모순입니다. 흔하지 않고 신선한 것이 사람들의 이목을 끕니다. 하지만 알고리즘이 사람들의 이목을 끄는 것들이 어떤 것인지를 발견한 뒤 이를 이용하기 시작하면 이것들의 가치는 떨어집니다. 소수의 사람만이 무언가를 할 때 그것은 사람들의 시선을 사로잡습니다. 하지만 모두가 같은 무언가를 할 때, 이미 그것은 그냥 지루한 것이 되고 맙니다. 트위터의 예로 돌아가서 “retweet”이나 “please”와 같은 단어를 트윗에 사용하는 것이 리트윗 수를 늘린다는 사실이 발견되었습니다. 하지만 모두가 이 단어를 사용하기 시작하면 그 효과는 사라지게 됩니다.
마지막으로 가장 높은 예측력을 보이는 변수 자체가 순환 논리에 빠져 있는 경우들이 있습니다. 최근 발표된 다른 논문에서 연구자들은 페이스북에서 어떤 포스팅에 가장 많은 댓글을 가져오는지를 조사했습니다. 포스팅에 달리는 댓글 수를 예측하는 데 있어 가장 예측력이 높았던 변수는 첫 번째 댓글이 얼마나 빨리 달리는가였습니다. 이 발견은 페이스북으로 하여금 당신에게 어떤 포스팅을 선별적으로 보여줄지를 결정하도록 돕고 있습니다. 하지만 이 결과는 댓글이 많이 달리는 포스팅을 어떻게 작성하면 되는지에 대해서 아무런 도움도 주지 못합니다. 실험 결과는 말합니다. “사람들이 좋아하는 포스팅을 작성하고 싶으세요? 음… 그렇다면 사람들이 좋아하는 포스팅을 작성하세요!”
빅 데이터는 놀랍지만, 마술이 아닙니다. 항생제, 전기, 그리고 컴퓨터와 같이 빅 데이터 이전의 훌륭한 발명품들이 그랬듯이 빅 데이터 역시 빅 데이터가 훌륭한 일을 수행할 수 있는 영역이 있고 별 도움이 안 되는 영역도 있습니다. (NYT)