넷플릭스는 어떻게 할리우드 영화를 분해하는가
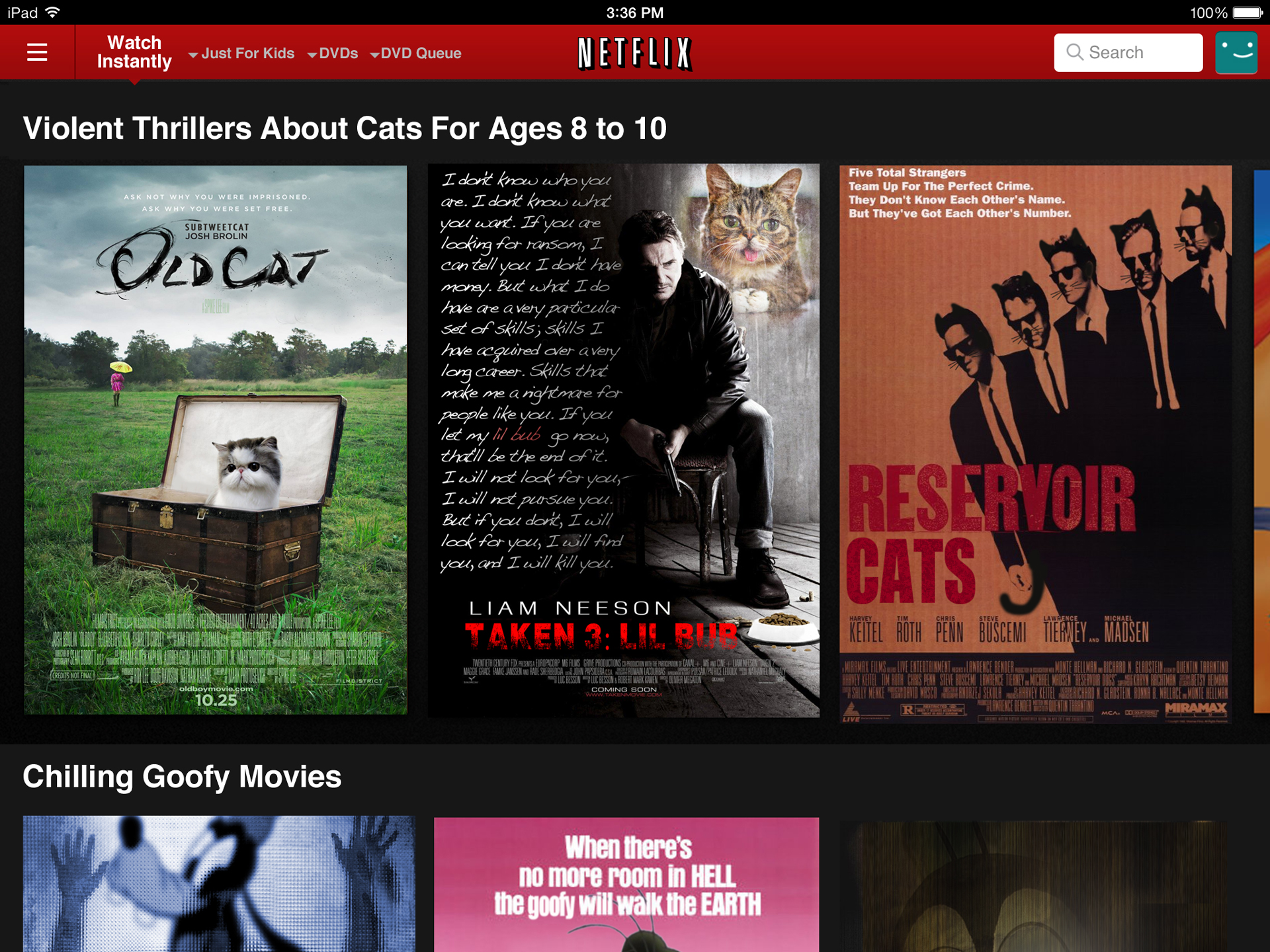
넷플릭스의 굉장히 구체적인 영화장르 구분이 우스갯소리처럼 거론된 적은 많습니다. “시스템에 맞서싸우는 가슴뭉클한 다큐멘터리” “실화에 기반한 충성심에 대한 시대물” “사탄에 관한 1980년대 외국 영화” 식으로 굉장히 구체적이죠. 도대체 넷플릭스에는 몇 개의 영화장르가 있는 걸까요?
처음에는 저도 가볍게 분석을 시작했습니다. 트위터를 통해 장르 이름을 모으다가, 넷플릭스의 ID 시스템을 알게 되어 스크립트를 써서 모든 URL 밑에 있는 장르이름을 스크랩해 왔죠. 분석해볼수록 끝도 없이 많은 겁니다. 무려 76,897 개의 장르를 찾았고 읽고 복사에 붙여넣으며 정리하는 데만 20시간을 보냈습니다. 몇 주 동안 작업을 하면서 파악한 넷플릭스의 장르 로직입니다. “어느 지역영화(Region)+ 부사(Adjectives) + 명사 장르(Noun Genre) + ~에 기반한(Based On…) + 배경은 어디이며(Set In… )+ 누가 만들었고(From the…) + ~에 관한 것이며(About…) + 타겟연령대는 X에서 Y임(For Age X to Y)” 이런 식이죠. 그러다보면 아래처럼 고양이에 관한 폭력적인 스릴러, 타겟 연령대는 8~10살. 이란 장르가 나옵니다. 이 추천 장르는 소비자가 보는 첫 화면의 제일 위에 뜨는데, 소비자가 다음 영화를 찾는 데 큰 역할을 하고 잇습니다.
궁금증을 못견딘 저는 결국 넷플릭스를 찾아가 인터뷰를 요청했고, 넷플릭스식 세부 장르를 개발한 상품혁신총괄(VP of Product Innovation) 토드 옐린(Todd Yellin)을 만나 개발 과정 뒷이야기를 들을 수 있었습니다. 넷플릭스는 메타데이터를 작성하기 위해 36페이지짜리 문서를 따라 꼼꼼하게 각 컨텐츠의 정보를 채워넣습니다. 내부적으로 넷플릭스 양자이론 (Netflix Quantum Theory)이라 불리는 프로젝트는 영화를 구성하는 “양자”가 무엇인지 모두 기록합니다. 성적인 컨텐츠는 얼마나 나오는지, 얼마나 잔인한지, 로맨틱한 정도는, 주인공은 얼마나 도덕적인지, 해피엔딩인지 아닌지까지 모든 정보를 1~5점 점수로 입력합니다. 플롯에는 어떤 이야기가 나오는지 정리하고, 주인공의 직업, 장소 정보를 입력합니다. 그리고 기계가 이에 기반해 ‘맞춤화 장르’ 를 만듭니다. 이런 정보는 어떤 장르의 TV쇼가 인기를 끌지도 알려주는데, 넷플릭스가 폭발적인 인기를 끈 하우스 오브 카드 (House of Cards)를 제작하게 된 것도 우연이 아니죠. (관련 뉴스페퍼민트 기사)
제 흥미를 끈 점은 맞춤화 장르를 만드는 과정에 컴퓨터의 알고리즘과 인간의 지성이 같이 활용된다는 겁니다. 컴퓨터는 같은 태그가 계속 반복되면 새로운 장르를 생성하는데, “해피엔딩 점수 5점짜리 모음” 의 경우는 인간 지성이 개입하여 “행복해지는 영화” 라는 그럴듯한 이름을 같이 달아줍니다. 다른 컨텐츠 회사들이 영화 별점을 분석하는 동안 넷플릭스는 훨씬 “인간답게” 느껴지는 추천방식을 도입하려 했지요. 넷플릭스도 소비자가 특정영화에 별점 얼마를 줄지 예측하는 알고리즘에 많은 투자를 하고 있으나 소비자에게 새로운 영화를 추천하는 단계에서는 “당신이 3.5점을 줄 영화” 라고 표현하기보다 아주 구체적인 장르를 마음에 와닿게 표현합니다. 1) 이름이 50자를 넘으면 안되고 2) 넷플릭스가 해당 장르 영화를 충분히 보유하고 있어야하며 3) 그 장르 이름이 문법적으로 말이 되어야 일반 고객에게 노출합니다. 기계가 가진 정보를 모두 노출하지 않고 스토리텔링을 하는 게 인상적입니다.
일반적인 개인화 추천 시스템은 당신이 좋아하는 영화를 본 사람들이 어떤 다른 영화를 좋아했는지 분석하는 식입니다. 그러나 넷플릭스는 행태 분석 대신에 컨텐츠 분해에 나섰죠. 판도라의 뮤직 게놈프로젝트와도 비슷한 형태입니다. 이를 보면서 페이스북의 뉴스피드도 모든 웹컨텐츠를 분석해 해체할 수 있을까, 라는 생각이 들었습니다. 너무 방대한 정보라 말도 안된다고 생각할 수도 있지만, 넷플릭스가 처음 이 프로젝트를 시작했을 때도 모두들 그렇게 생각했을 겁니다. (The Atlantic)