조금 전 끝난 라파엘 나달과 케빈 앤더슨의 남자 단식 결승전을 끝으로 올 US오픈 테니스 대회도, 2017년 메이저 대회 일정도 모두 마무리됐습니다. 어제 여자 결승전에선 신예 슬로안 스티븐스가 강호를 잇달아 연파하고 깜짝 우승을 차지했죠. 오늘 하려는 이야기는 테니스 경기 관련 뉴스가 아닙니다. 오늘은 하버드대학교 경제학과의 센딜 뮬레네이선 교수가 뉴욕타임스 업샷에 쓴 칼럼을 소개하려 합니다. 칼럼의 제목은 “Sexism and Shopping: Female Players Get Most of the Odd Questions at the U.S. Open”입니다.
—–
코트 위에서 남자 선수와 여자 선수에게 적용되는 규칙은 똑같습니다. 남자는 5세트 가운데 3세트를 먼저 이겨야 승리하고, 여자는 3세트 가운데 2세트를 먼저 이겨야 하는 점만 다르죠. (이것도 4대 메이저 대회에서만 그렇습니다. 나머지 ATP 투어에서는 남자도 2세트만 이기면 승리합니다.) 그러나 경기가 끝난 뒤 인터뷰와 기자회견장에서 남녀 선수들이 겪는 상황은 서로 꽤 다릅니다.
대표적인 사례 몇 가지만 들어보겠습니다. 2년 전 세레나 윌리엄스는 왜 웃지 않느냐는 질문을 받았습니다. 아마도 남자 선수에게는 잘 하지 않았을 법한 질문이죠.
“연습을 마치고 나서는 테니스 생각은 잠시 접어두고 근사한 저녁도 먹고, 쇼핑도 하고, 뭔가 재미있는 일도 찾아서 하시는 거죠?”
2012년 호주 오픈에서 한 선수가 받은 질문입니다. 이 선수의 성별이 무엇이었을지는 모두 어렵잖게 짐작하실 수 있을 겁니다.
리예 푸, 크리스찬 다네스쿠-니쿨레스쿠, 릴리안 리는 코넬대학교 소속 컴퓨터 과학자입니다. 이들은 위에 언급한 사례가 이례적인지 아니면 흔히 일어나는 일 가운데 하나일 뿐인지를 검증하고자 알고리즘을 짰습니다. 이들은 지난 15년간 테니스 대회에서 선수들이 받은 질문 수천 개를 모두 모은 뒤 이 알고리즘을 통해 성별에 따라 질문의 내용이 다른지 살펴봤습니다.
테니스에 아무런 관심이 없으시더라도 이 연구는 흥미롭게 지켜볼 만한 가치가 있습니다. 단지 미묘하지만 끈덕지게 남아 있는 우리 사회의 성차별과 편견을 드러내는 연구라서 그런 것이 아닙니다. 이들이 어떻게 이번 연구를 수행했고 결과를 도출했는지 이해하면 전반적으로 알고리즘이라는 것이 어떻게 작동하는지 이해하는 데 큰 도움이 될 겁니다. 인간의 본질적인 행위라 할 수 있는 언어를 도대체 어떻게 알고리즘으로 접근하고 이해할 수 있을까요? 누구나 한 번쯤 의심은 했을 테지만 증명할 방법이 없어 포기했을 그 미묘한 성향을 밝혀내는 데 알고리즘이 어떤 역할을 했을까요?
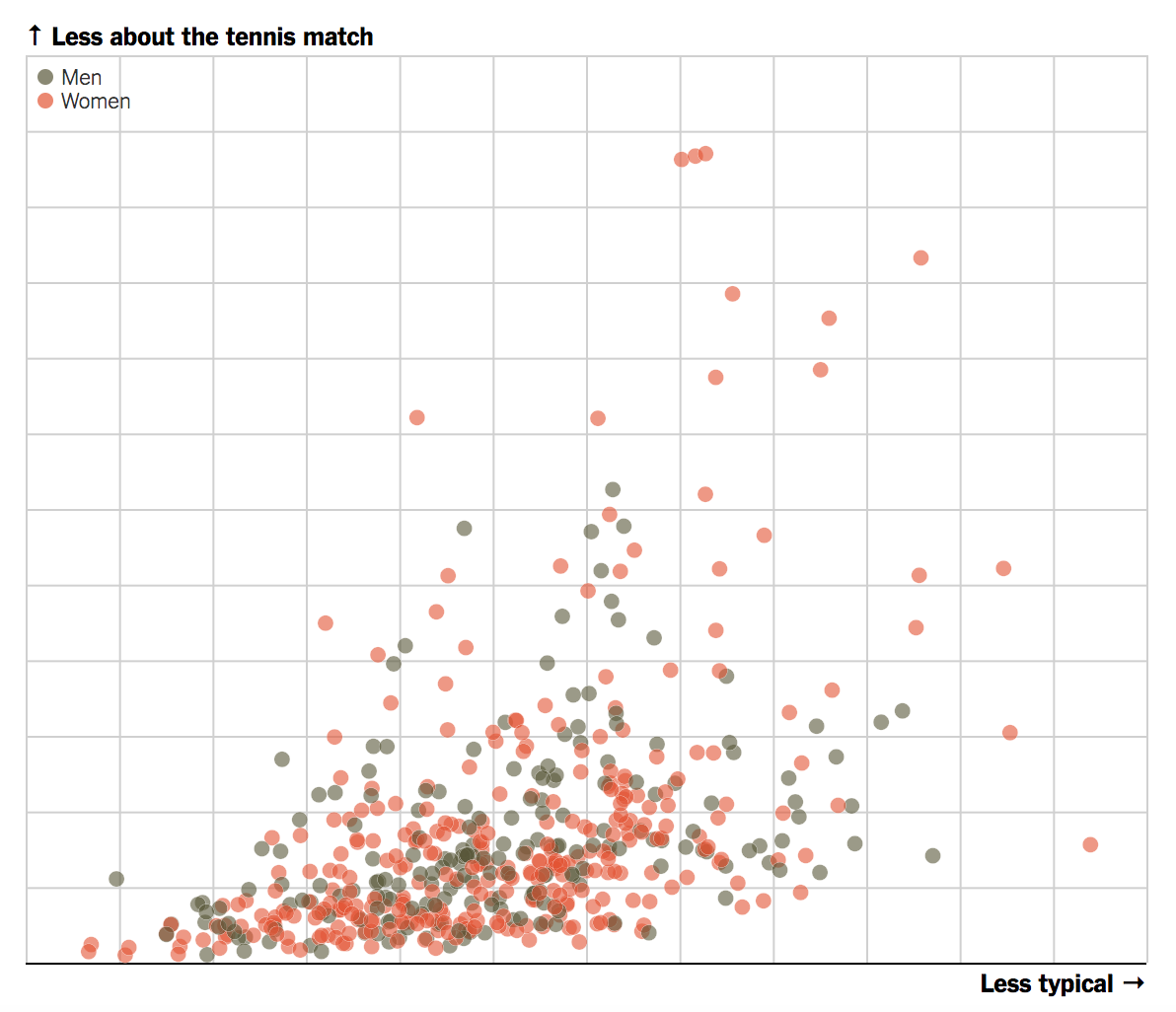
우선 지난해 코넬의 과학자 세 명이 발표한 연구 내용부터 살펴보겠습니다. 결론부터 말하면 세레나 윌리엄스가 받은 “왜 잘 웃지 않느냐?”는 질문은 전혀 예외가 아니었습니다. 테니스 선수가 받은 모든 질문을 분석한 알고리즘이 내놓은 결론을 한마디로 요약하면 테니스와 관련 없는 질문은 대개 여자 선수들에게 집중됩니다. 기본적으로 선수들에게 하는 판에 박힌, 전형적인 질문들을 제외하고 나면 엉뚱하거나 잘 하지 않는 질문, 대개 테니스와 관련 없는 질문이 남는데, 이 가운데 70% 정도가 여자 선수들에게 한 질문이었습니다.
올해 US오픈에서 나온 질문 528개를 분석한 결과도 다음과 같습니다. 테니스와 크게 관련 없는, 판에 박히지 않은 질문은 대개 여자 선수가 받았다는 걸 알 수 있죠.
(남자 운동선수가 그런 질문을 받았을 때 어떤 반응을 보이는지, 그런 질문을 한 기자가 얼마나 자격 미달인지 보여주는 패러디 비디오도 있습니다)
연구진에게 해당 알고리즘으로 올해 메이저 대회에서 나온 질문들을 분석해보면 어떤 결과가 나오는지 확인해달라고 부탁했습니다. 먼저 남자 선수들이 받은 판에 박힌 질문들, 의례적인 질문들은 아래와 같습니다.
“오늘 같은 경기 전에 어떤 식으로 준비를 하세요?”
“US오픈 2주 차를 맞았습니다. 아직 토너먼트에 남아 더 높은 곳을 향해 가고 계시죠. 기분이 어떠신가요?”
여자 선수들이 받은 판에 박힌 질문들도 테니스와 관련된 것이 대부분이니 크게 다르지 않습니다.
“다음 경기는 어떻게 될 거라고 예상하세요?”
“부상으로 재활 기간을 거친 뒤 복귀한 대회에서 상당히 힘든 접전을 펼치셨죠. 그래도 US오픈에서 경기하는 게 선수로서 특별한 점이 있다면 뭐가 있을까요?”
이번에는 흔히 접할 수 없는, 테니스와는 관련 없는 엉뚱하고 이상한 질문들입니다. 먼저 남자 선수들이 받은 질문들 가운데 다음과 같은 질문이 있습니다.
“경기 중에 스스로 믿지 못하겠거나 의심이 들던 순간이 있었나요?”
“당신이 ‘키 작은 사람들의 희망’이라는 말이 있어요. 어떻게 생각하세요?”
여자 선수들도 테니스와 관련 없는 질문을 받습니다.
“경기장에 와서 매니큐어 바르고 손톱 단장하는 선수가 있나요? 혹시 아세요?”
“쇼핑 가면 꼭 이거는 사는 아이템이 있다면요?”
알고리즘은 어떻게 이런 질문들을 가려낸 걸까요? 어떤 질문은 테니스와 관련이 있고, 어떤 건 관련이 없는지는 무슨 기준으로 판단했을까요?
알고리즘이 언어를 이해하고 처리하는 데 왜 유용한지부터 알아보는 것이 순서일 겁니다. 연구에 쓰인 알고리즘을 예로 들면 먼저 이 알고리즘은 우리가 어떤 주제나 단어를 테니스와 관련 없는 것으로 생각하는지 알아내야 합니다. 그런데 이 작업을 컴퓨터 없이 한다면 어떨지 한 번 상상해 보세요. 한없이 복잡하고 미묘하며 상황에 따라 조금씩, 하지만 분명히 뜻이 다른 게 언어이다 보니, 대회에서 선수들이 받는 질문도 마찬가지로 엄청 다양하죠. 이 질문을 하나하나 사람이 듣고, 읽고 분석해 분류한다면 여기에만 엄청 긴 시간이 들 겁니다. 반대로 컴퓨터의 연산 능력을 기반으로 하는 알고리즘은 순식간에 수천, 수만 개 질문을 바로 확인하고 분류할 수 있죠.
물론 어떤 식으로 연산을 수행할지 정확한 명령을 내려야 하지만, 어쨌든 이 연산 능력은 그 자체로 대단한 능력입니다. 우선 알고리즘이 무엇을 어떻게 했으면 좋은지 막연하게 방향은 잡혀 있습니다. 먼저 테니스와 관련된 표현, 언어, 질문이 어떤 것들인지 인지하고 학습해야겠죠. 그렇지만 처음부터 쉽지 않은 문제에 부딪힙니다. 어떤 언어의 조합이, 무슨 표현이 테니스와 관련된 것인지 어떻게 알아낼까요?
코넬 연구진은 이 난관을 정말 무릎을 탁 칠 만한 방법으로 돌파했습니다. (테니스와 관련된) 다른 데이터를 알고리즘이 학습할 수 있게 한 것이죠. 테니스에 관한 말이라면 경기가 끝난 뒤 선수와 주고받는 인터뷰가 전부가 아닙니다. 경기를 해설하는 중계진의 말도 다양하고 풍부하죠. 중계진의 해설을 분석하면 어떤 말이 테니스와 관련된 것이고, 어떤 말은 관련이 없는 것인지 판단하는 데 필요한 기준이 섭니다.
경기 후 선수들이 받는 질문을 분석하는 알고리즘은 바로 경기중 해설을 데이터로 학습한 것입니다. 질문에 쓰인 단어나 언어 구조, 표현이 경기중 중계진과 해설자가 쓴 말과 얼마나 닮았고, 어떻게 다른지를 분석해 이 질문이 테니스에 관한 질문인지 여부를 추론하는 겁니다.
이렇게 질문들을 분석한 결과 성별에 따른 편견이 여과 없이 드러났습니다. 물론 알고리즘은 질문을 받는 선수가 남자인지 여자인지 모른 채 언어를 분석하고 처리합니다. 하지만 분석 결과를 남녀에 따라 나눈 뒤 비교하는 작업은 연구진이 쉽게 할 수 있는 작업이죠. 해당 경기와 대회, 테니스 전반에 관한 전형적인 질문을 제외하고, 판에 박히지 않은 특별하거나 엉뚱한 질문만 살펴보기 위해 연구진은 해당 질문이 얼마나 흔한지 점수를 추가로 매겼습니다. 이제 남은 일은 간단합니다. 테니스와 관련된 질문/관련 없는 질문을 남녀 각각 얼마나 받았는지 살펴보는 것이죠.
주지하다시피 테니스와 관련 없는 엉뚱한 질문을 받은 건 주로 남자 선수보다 여자 선수였습니다.
다만 이러한 편견을 알고리즘이 스스로 발견해낸 것이 아니라는 점이 중요하다는 걸 다시 한번 강조하고 싶습니다. 이 연구가 더욱 뛰어난 이유는 결국 알고리즘이 수행한 연산보다 중요한 건 사람의 판단이라는 사실을 일깨워주기 때문입니다. 질문에 내재된 편견을 밝혀낸 주체는 알고리즘이 아닙니다. 자연언어처리(natural language processing) 분야의 최고 연구진이 몇 달에 걸쳐 쏟아부은 지적 노동의 결과 편견이 구체적인 수치로 모습을 드러낸 겁니다.
이러한 성과를 기계의 능력이나 인공지능 덕으로 돌리면 우리는 종종 잘못된 결론을 내리게 됩니다. 우리는 아마 머지않은 미래에 스스로 쌓은 통찰력을 발휘하는 기계를 마주하게 될 것입니다. 이미 영상이나 음성 인식 및 처리장치는 상당 부분 자동화됐습니다.
상당히 많은 분야에서 창의성과 지적 능력이 비약적인 발전을 이룩했습니다. 우리는 이를 대개 기술의 혁명적인 발전 덕분으로 돌리곤 합니다. 하지만 진정한 기술 발전은 인간이 기반 기술을 현명하게 활용할 때만 가능하다는 점을 잊어서는 안 됩니다. 인공지능도 마찬가지입니다. 인공지능의 등장으로 인간의 지적 능력과 판단력은 오히려 더 중요해졌습니다. 과학을 장착한 기계를 의인화해 기계 자체를 칭송하는 건 문제의 본질을 헛짚는 것입니다.
15세기 선원근법의 등장은 회화의 혁명을 불러왔습니다. “아테네 학당” 같은 희대의 걸작은 새로운 구도를 가능하게 한 선원근법이 없었다면 불가능했을 겁니다. 우리가 선원근법 자체를 의인화해 칭송하지 않는 것처럼 인공지능 덕분에 가능해진 새로운 기술의 공로도 인공지능 그 자체에 있다고 해서는 안 됩니다. 아무리 선원근법이 혁명적이었다고 해도 “아테나 학당”이란 걸작을 그려낸 라파엘로보다 더 소중한 인류의 자산은 아니니까요. (뉴욕타임스)
뉴스페퍼민트가 SBS의 콘텐츠 플랫폼 스브스프리미엄(스프)에 뉴욕타임스 칼럼을 한 편씩 선정해 번역하고 함께 쓴 해설을 스프와…
뉴스페퍼민트가 SBS의 콘텐츠 플랫폼 스브스프리미엄(스프)에 뉴욕타임스 칼럼을 한 편씩 선정해 번역하고 함께 쓴 해설을 스프와…
뉴스페퍼민트가 SBS의 콘텐츠 플랫폼 스브스프리미엄(스프)에 뉴욕타임스 칼럼을 한 편씩 선정해 번역하고 함께 쓴 해설을 스프와…
뉴스페퍼민트가 SBS의 콘텐츠 플랫폼 스브스프리미엄(스프)에 뉴욕타임스 칼럼을 한 편씩 선정해 번역하고 함께 쓴 해설을 스프와…
뉴스페퍼민트가 SBS의 콘텐츠 플랫폼 스브스프리미엄(스프)에 뉴욕타임스 칼럼을 한 편씩 선정해 번역하고 함께 쓴 해설을 스프와…
뉴스페퍼민트가 SBS의 콘텐츠 플랫폼 스브스프리미엄(스프)에 뉴욕타임스 칼럼을 한 편씩 선정해 번역하고, 함께 쓴 해설을 스프와…
{kind=link}